For the v1.8.6 the development was focused on two main objectives :
-
the child mode
-
headlines feature
1. Child mode
Regarding the child mode, a new checkbox appeared in the settings. It allows to enable the child mode, in which only child compatible sources are available (and access to settings and source creation is removed from the main interface).
This is intended for school purposes. With this feature, you can turn your back a few minutes while kids are using the tool. As long as they are on the main interface, they’re safe.
When you need to disable the child mode, reach the settings via the Firefox'
standard way of reaching the settings of a WebExtension (via the menu or the
about:addons internal address).
The sources available when the child mode is activated are marked with the for kids tech. tag, so you can easily list them to check them via the source list feature of the main interface. Two other tags have been set : for kids < 9 and for kids > 9 ; to address specific needs of a thinner audience based on it age.
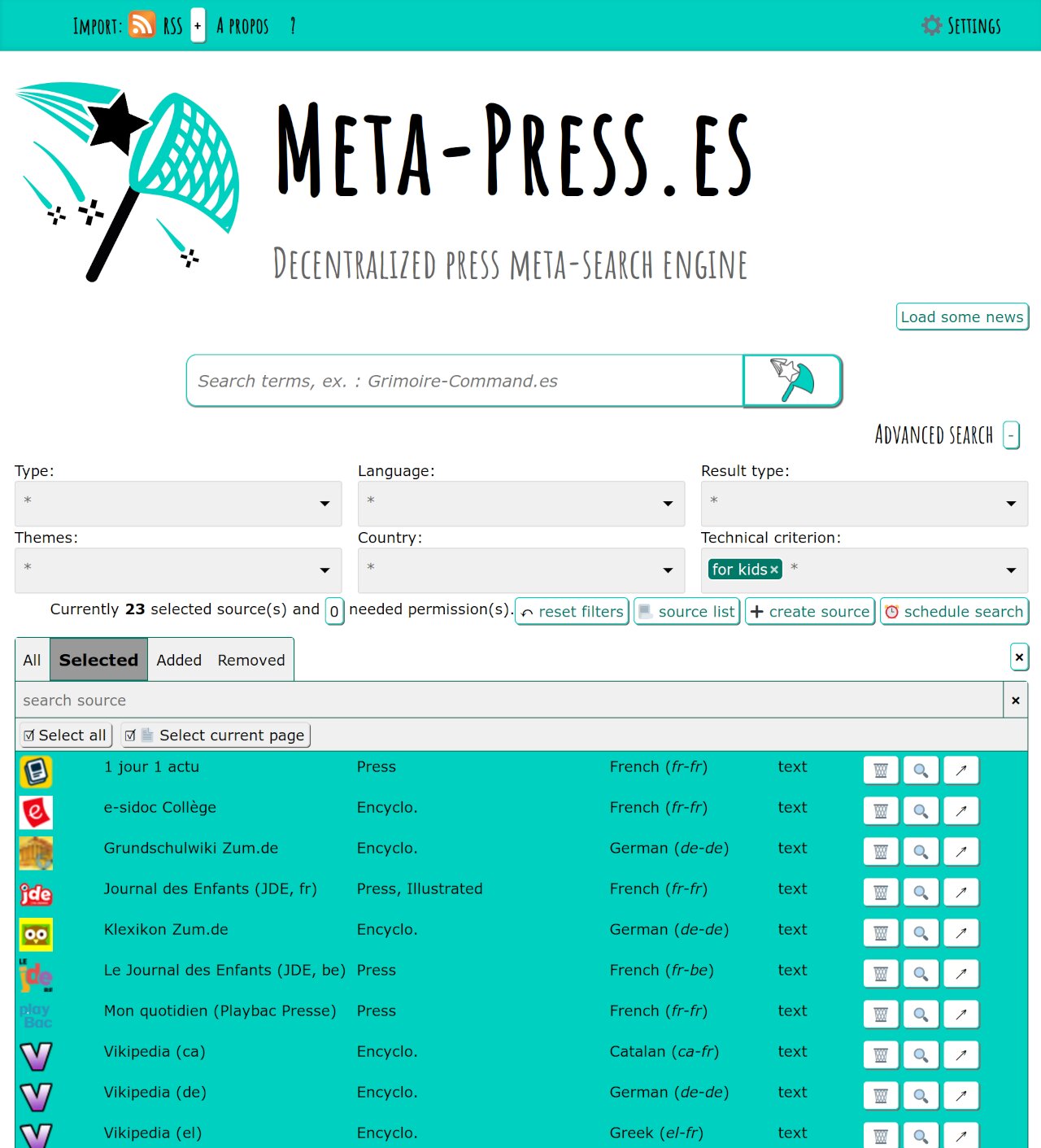
Currently 26 sources are marked for kids and I warmly encourage you to send me references to more sources for this category.
All the instances of Vidipedia and Wikikids have been added to Meta-Press.es as declared in this post : https://pouet.chapril.org/@metapress/108770494843123872

Par Ziko van Dijk — Travail personnel Map children wiki encyclopedias in Europe Jan 2015.pdf, CC BY-SA 4.0, Lien
2. RSS news feeds
Regarding the headlines, a radical change occurred. Headlines are now fetched from main RSS feeds of sources (if they provide one). This brings 3 main advantages :
-
every compatible source can now provide up to 10 general purpose news (your setting)
-
those news are now fitted with excerpts in addition to titles
-
half of the compatible sources now provide illustrations
Meta-Press.es is not to become a general purpose news feed reader, but it is now a news feed reader for its indexed sources.
Settings have been added to chose how many news to display from each sources.
On my own Meta-Press.es instance, I saved a new "scheduled search" setup with
my favourite independent sources (among current 224 ones). I let it on its
default "Stop" run frequency and I open it from the settings only to load the
news ! Also, the indep. tag is not a source type anymore but a tech tag that
can be crossed with many source types (such as: encyclo. press agenda …).
This new feature was introduced thanks to a modification in the source definition API. I scripted the upgrade for the current 600+ sources and half of them was found to provide an RSS feed. Maybe some are missing for sources you know, don’t hesitate to signal them, it’s easy to add back for the next release.
This was a simplification trade between the headline_url + h_title selectors in source definitions for a single news_rss_url and even if we’re losing half the sources currently, it’s removing the heaviest maintenance burden. 2/3 of the source upgrading tasks where about the headlines (as the frontpage of newspapers is constantly evolving). The only foreseeable evolution in RSS news feeds are their possible removal, but they have been doomed dead long ago already.
Another modification that this work introduced in the source definition API was
the removal of the xml_type entry. No need anymore. The work on the dynamic
source creation form (introduced in v1.8.5) lead to the creation of a
"detect_RSS_variant" function, that were re-used and battle proven for RSS
headline fetching and so extended to the search feature of RSS based source
definitions. So defining a new source is a bit easier now in the case of RSS
based sources, and the new source creation form have been updated accordingly.
An expected visible effect is more illustrations on results (because we might have missed some with the previous "manually setup" system).
The online documentation have been update also. (and it’s the kind of lines that do not reflect the work it have been).
3. Fancy or serious sources
Aside to sources that should be easy to index, but finally provides bad RSS results like the DailyTelegraph.com or Arabnews.jp (the two of them were discovered the same day) :
Big up for the #DailyTelegraph which manage to publish a half empty #RSS feed without any date on entries !! https://www.dailytelegraph.com.au/news/breaking-news/rss Over 235 RSS feeds, its the deadliest broken one. The good news is that you'll be able to fetch all the other feeds from the next version of #MetaPress.
- 9 août 2022 à 19:25 - https://pouet.chapril.org/@metapress/108794553815547789
There is a source that is hard to work with. It’s the serious
IntelligenceOnline.fr dealing with infosecs
(sounds great). This source already lead to some improvements in the source
definition API of Meta-Press.es like the new search_ctype which allows to
specify the content-type used to send the request to the server (every 608
currently working sources are using application/x-www-form-urlencoded, but
this one requires application/json). But it’s not enough to work with
IntelligenceOnline as this source also encode (maybe encrypt) the search terms
before it sends them to the server… OK, why not. As it’s all open-hearted
client-side JavaScript, the exact mechanism might be studied and a cipher key
might be extracted and I would love to enrich Meta-Press.es source definition
API with term_cipher_method and term_cipher_key entries.
As it wont be in my priorities anytime soon, a contributer might earn a lot of consideration, some Meta-Press.es stickers and badges, and an in-depth blog-post here (10k visitors a month) diving into this problem. An issue were created to track this subject : https://framagit.org/Siltaar/meta-press-ext/-/issues/54
| 2024-02-26: a mechanism of preliminary request to grab a token to inject into the search URL have been implemented. It fixes this issue. |
To finish, some new tendencies… Some sources are still using jsonp to serve
results (it’s a workaround CORS limitations on JSON that was heavily used 20
years ago). It’s the case of LaNacion.com.ar (OK, it’s the south-half of the
word, with an insane climate and a terrible economic crisis 20 years ago…) and
Liberation.fr. So it exists a jsonp_to_json_re entry for source definitions
that allows to specify a RegExp used to extract the JSON data the JSONP script
source file.
But a something new is emerging and appears to be the contrary : JSON is used
to encapsulate server-side computed regular HTML… Why not sending bare HTML ?
Still, the new json_to_html source definition entry allows to extract and
parse the HTML. I imagine that I’ll have to detail this mechanism on a
per-field level soon.
 Installation via Mozilla
Installation via Mozilla
 Sources via Framagit
Sources via Framagit
 Sponsor via Liberapay
Sponsor via Liberapay
 Sponsor via HelloAsso
Sponsor via HelloAsso
 Social via Mastodon
Social via Mastodon
 Wau Holland Stiftung
Wau Holland Stiftung
