
Documentation
Index
1. What is it?
Meta-Press.es is a tool to search the online press (international reference press, specialized reviews, general purpose press…). It can be used to make press reviews for big associations for instance or scientific press coverage (via dedicated sources). Researches are keyword driven and you can select precisely in which sources to search (via type, language, theme, result type…). So users have full control over the sources queried to perform their searches and they even can add their own sources.
Then it’s possible to schedule daily searches (or monthly ones).
This search engine is shaped as a web browser addon (WebExtension standard format). The search and sort job is handled by the the extension itself, on the computer of the user and it allows to gives the user fine grained control over the tool.
Meta-Press.es is already able to search through hundreds of sources and this number regularly grows.
Using Meta-Press.es, there is no central server involved, to watch over and profile users, to adapt search results to their behavior and habits or to add targeted ads. So there is no bubble effect like with commercial mainstream search engines.
Meta-Press.es works great with the Tor Browser (which have been made, among other goals, to read the press with more confidentiality than with an ordinary web browser).
It’s otherwise recommanded to use the DNS resolver Quad9 (via Firefox for example) to avoid local administrative censorships.
It also works on Android via Fennec F-Droid an Android version of Firefox installable from the libre software catalogue F-Droid.
Meta-Press.es is a free / libre software with open sources. Those whom know HTML and JavaScript can explore its source code and adapt the tool to their needs (or easily add new sources).
To finish, Meta-Press.es is an energy efficient tool : there is no need for polar circle datacenters to perform searches through the online press…
1.1. Limits
Limits of Meta-Press.es are to search only through recent news (access to older results will be available in the future), to only sort results by chronological order and to need users to install a web browser addon…
2. How does it work?
Meta-Press.es is a meta-search engine that allows you to query the internal search engine of each source (knows to the system and selected for the search).
You will get the number of alleged results in all the sources, and the newest available results from each.
Newspapers are scrapped from the web (or RSS feeds of results), one by one. So you save, at each query, the time that the developpers spent parsing the newspapers :-)
Doing this Meta-Press.es won’t activate any ad. or social trackers of the queried newspapers, protecting your privacy, but it gives you back the choice of your information sources and clearly states in which source it searched.
Once you get the results, you can select and export some results in a re-usable format (RSS, jSON, CSV…). You’ll be able to re-import them later or use them somewhere else (send them by email to a friend, import them in a WordPress…).
3. How to install it?
To install Meta-Press.es on your Firefox-based web browser : load the following page in your browser addons.mozilla.org and click on + Add to Firefox big blue button.
4. How to use it?
Once installed, the add-on creates a new button in the toolbar decorated with the Meta-Press.es landing net icon.
Figure 1. button with the Meta-Press.es icon
A click on this button opens a new tab on the search engine interface.
If the button is missing in the toolbar, it might just be waiting for you behind the puzzle menu of the extensions of your web browser instead of being directly visible. You can pin it in the toolbar for direct access.
You might also haven’t given Meta-Press.es the right to run in private mode
during it’s installation (and be using this mode). In this case, it’s still
possible to give the authorisation via the list of add-ons of your browser (or
via the about:addons address).
By the way, you should check that the automatic updates are activated to be sure to always use the latest sources and features.

Figure 2. head of the search engine main interface
Under the Meta-Press.es logo and title, headlines from the selected newspapers are shown and rotated.
Then you can type your query and choose in which newspapers to search in, based on a multiple criteria filter mechanism.
Results are then listed right under, when they arrive.
Each result is composed of a title, and link, its source name, its date and potentially an author and an extract:

Figure 3. details of a result
Tools to work on results (sort, search, select) appear in the right column.
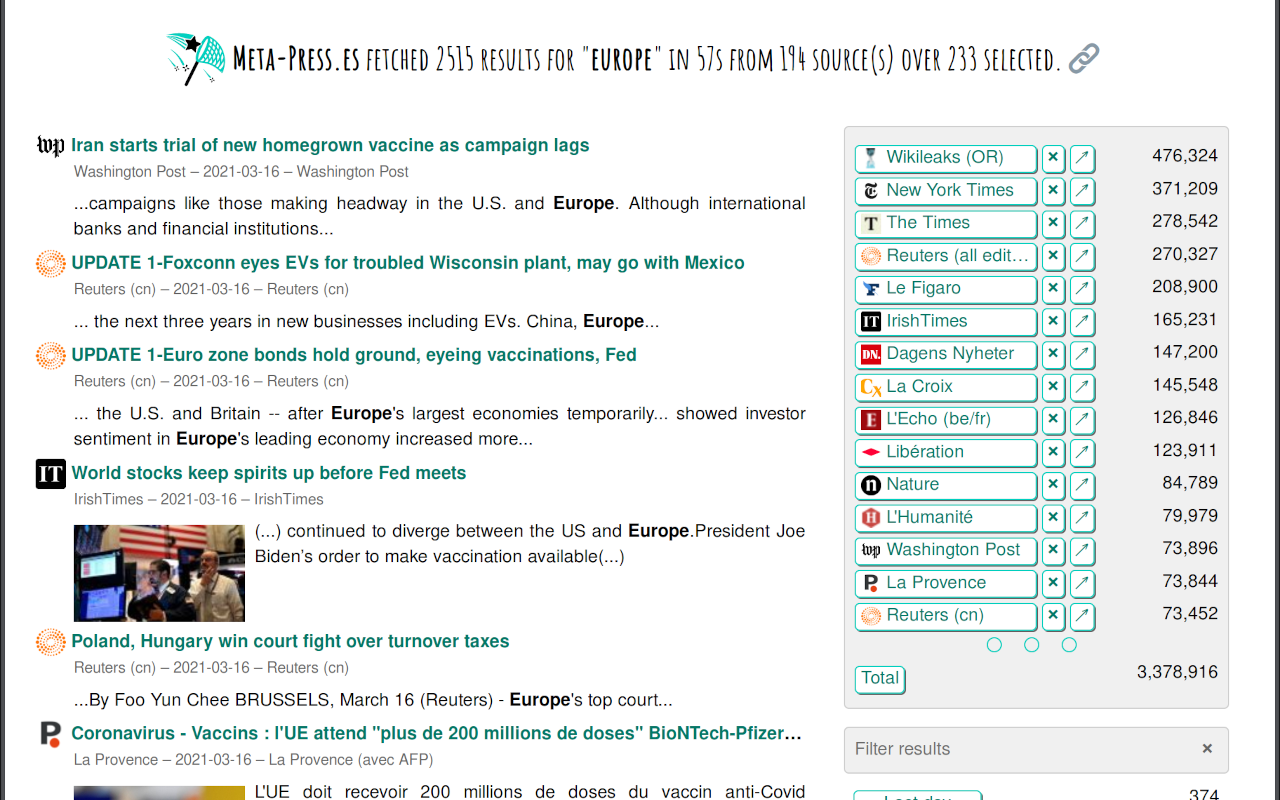
Figure 4. number of results by source and filter by source (clicking on its name)
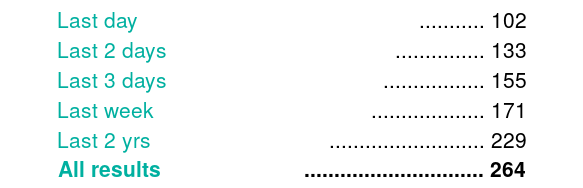
Figure 5. filter by date
You can, for example, click on the "Toggle selection mode" to display a checkbox for each result. You can then export your selection of checked results in various format (JSON, RSS, ATOM and soon CSV).
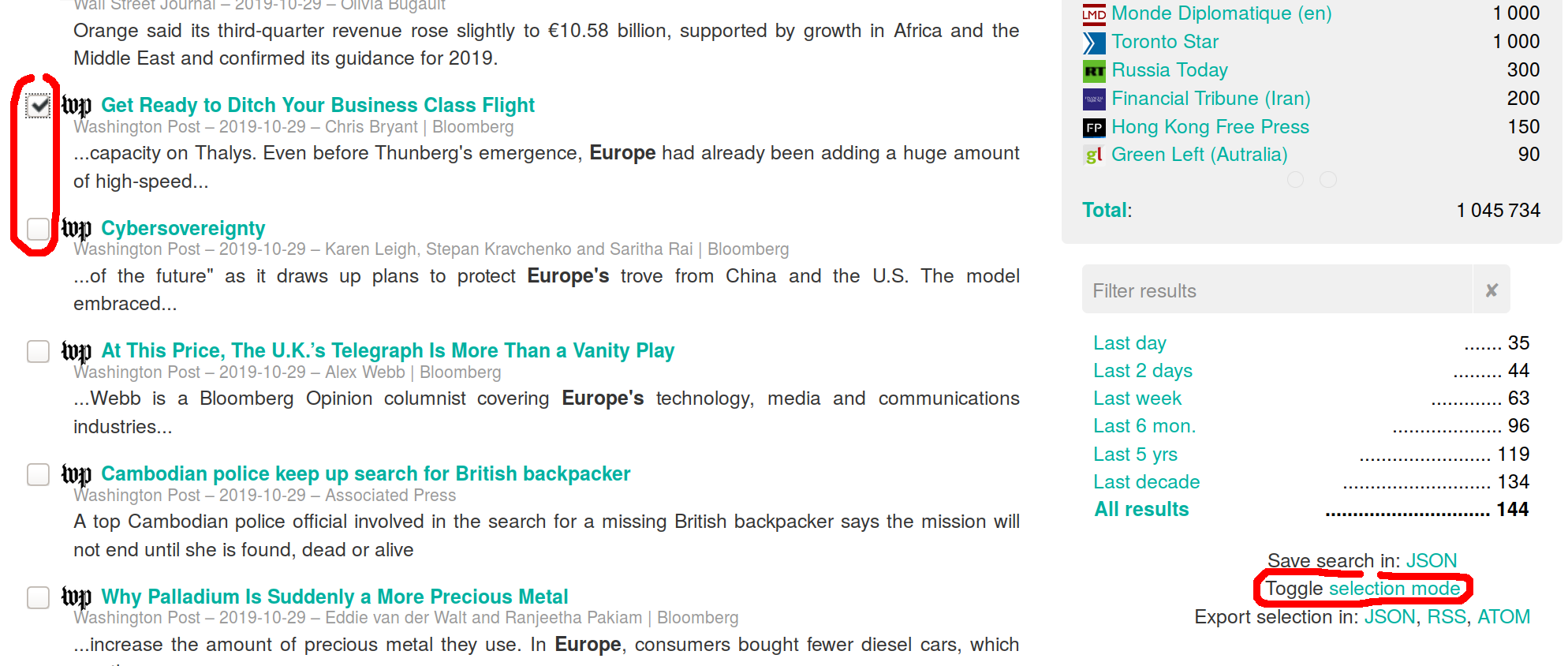
Figure 6. select mode
To re-import the search results, click on the "Import JSON" (or RSS, or ATOM) link in the cyan horizontal top bar, and select the file to import in the file picker that pops up.
4.1. Cherry-pick sources to search in
It is possible to select the sources you wanna query, one by one.
To do so, you first need to deploy the advanced search panel, clicking on the [ + ] sign in "Advanced search [+]" title. This will display 2 lines of source filtering criterion, and a line of buttons :
-
reset filters
-
list source
-
add source
-
scheduled search
A click on the "list source" button displays a 2nd panel showing the list of all the sources. Different tabs allow you add a specific source to the next search, or remove some others.
The "magnifier" icon, on each source line, set the next search to be performed in this specific source only.
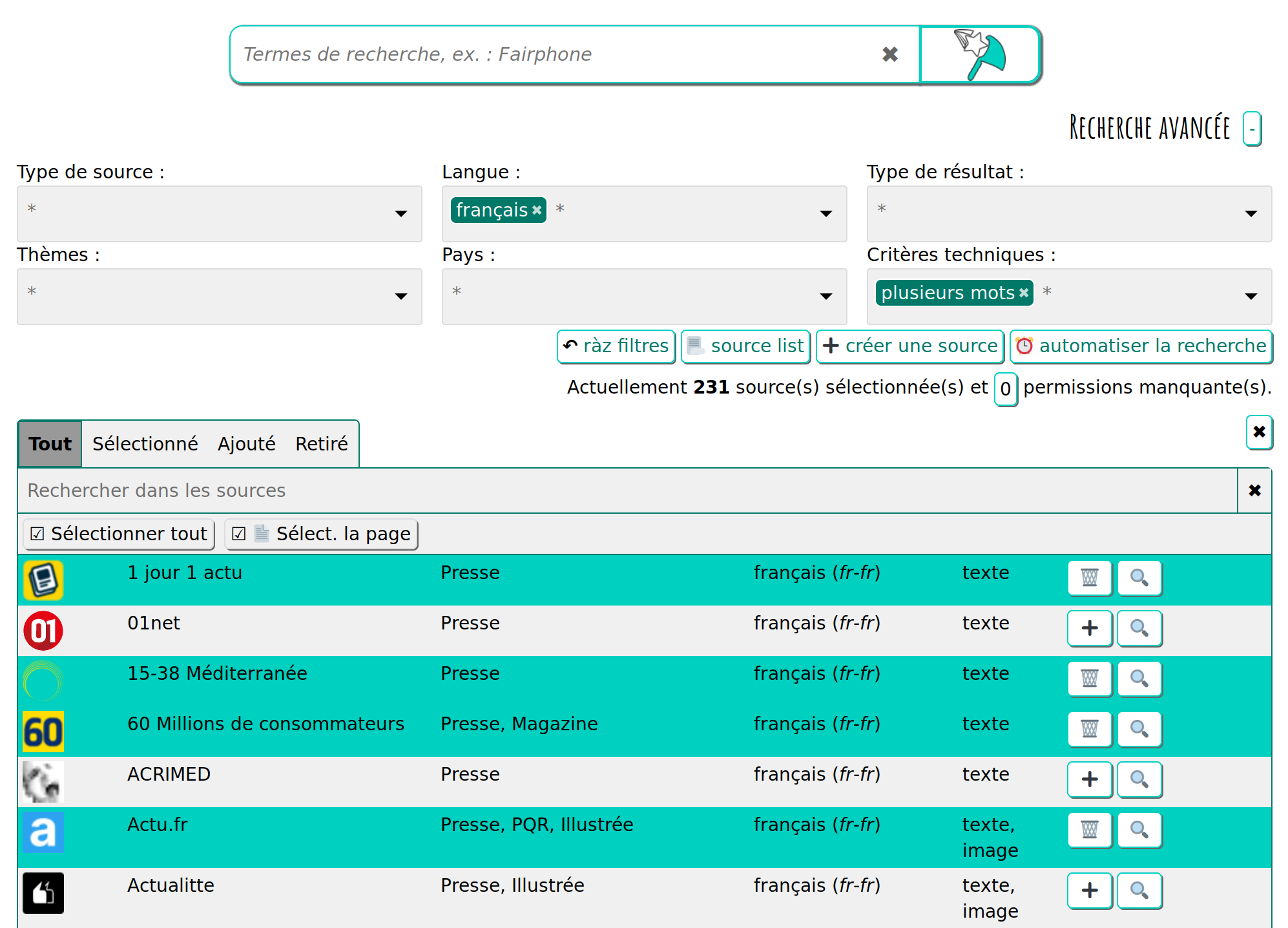
Figure 7. Cherry-pick sources
4.2. Permalinks and bookmarks
When a search is finished a statistics line appears on top of the listed results. This line is fitted with a 🔗 "chain link" icon at the end. This icon allows you to launch the same search again.

Figure 8. Search permalink icon
So it’s possible to create bookmarks for your favorite searches (sparing configuration time).
4.3. Scheduled searches
Once you typed your search terms and selected the sources you wanna search in, it’s possible to save the search for later instead of launching it immediately. It’s the role of the ⏰ Schedule search button under the source selection. This button opens a new tab on the "Settings" scrolled to the Scheduled searches part.
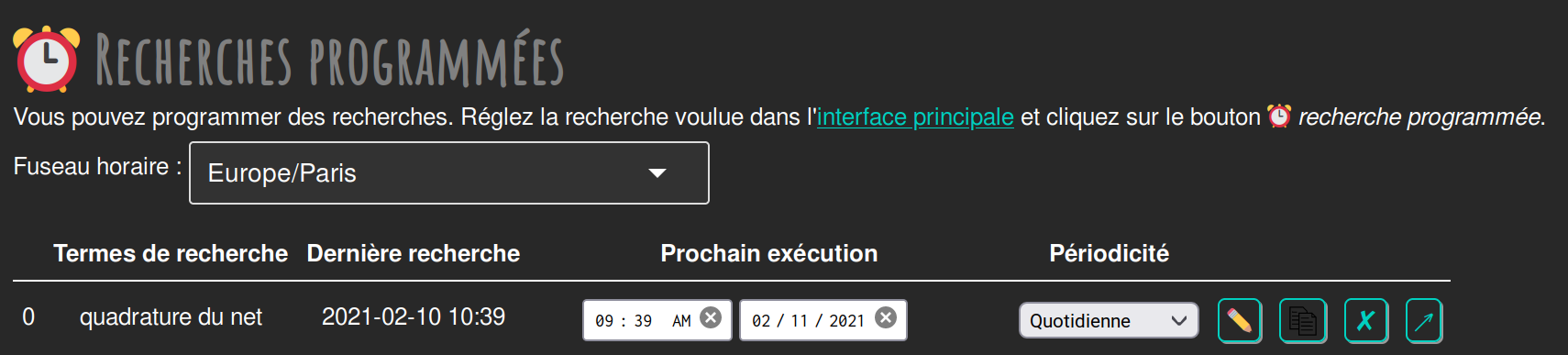
Figure 9. Scheduled searches, on dark background interface
This table shows a scheduled search by line. When created, a scheduled search is in "Stop" state, but you just have to select the date, time and periodicity you want for this search to have it activated.
So you can schedule a daily search in a few clicks.
Actions are possible on scheduled searches:
-
the ✏️ "pen" button allows to edit the search, it opens the main search interface with the scheduled search settings (search terms, source selection). Once modified, your search settings can be saved clicking on the "Schedule search" button of the main interface ;
-
the 2nd button, with a copy/paste icon, allows to clone a scheduled search to get another one, that you can configure with the previously described button ;
-
the 3rd button, with a cross on it allows to delete a scheduled search ;
-
the 4th and last button allows to manually start the search from the table.
5. How to add a new source to the search engine?
To add a new source to Meta-Press.es, simply click the "add new source" button of the main interface. This will open a new tab in which a form will guide you through the process, step by step.
This form currently works only for RSS served results from WordPress sources (around 50% of Meta-Press.es sources). It will be extended to other cases soon.
If you are a programmer, you just have to add an entry in the json/sources.json JSON object (or write your entry in the setting panel of the add-on).
An exhaustive documentation have been written to help you in this task.
 Installation via Mozilla
Installation via Mozilla
 Sources via Framagit
Sources via Framagit
 Sponsor via Liberapay
Sponsor via Liberapay
 Sponsor via HelloAsso
Sponsor via HelloAsso
 Social via Mastodon
Social via Mastodon
 Wau Holland Stiftung
Wau Holland Stiftung
