Pour la version 1.8.6 l’attention fut portée sur deux objectifs :
-
le mode enfant
-
le chargement des gros titres de l’actualité générale hors recherche ;
1. Mode enfant
Concernant le mode enfant une nouvelle case à cocher est apparue dans les réglages. Elle permet d’activer le mode enfant ce qui ne laisse plus que les sources étiquetées comme adaptées aux enfants de disponibles dans Meta-Press.es. De plus l’accès aux réglages et l’ajout de nouvelles sources ne sont plus accessibles depuis l’interface principale.
Cette fonctionnalité est destinée aux écoles, grâce à elle un prof. peut tourner le dos 5 minutes (pour faire le tour des postes de la classe) l’esprit serein. Tant que les élèves sont devant l’interface principale, c’est sans danger.
Pour désactiver le mode enfant, il faut atteindre les réglages depuis la liste
des WebExtensions de Firefox (soit via le menu de Firefox, soit via l’adresse interne
about:addons).
Les sources qui restent disponibles lorsque le mode enfant est activé sont étiquetées for kids dans le logiciel (et ce terme sera probablement traduit par "mode enfant" à l’affichage). Il est donc facile de les lister dans l’interface principale. De plus, les étiquettes for kids < 9 et for kids > 9 sont également disponibles pour cibler plus finement l’age de son audience.
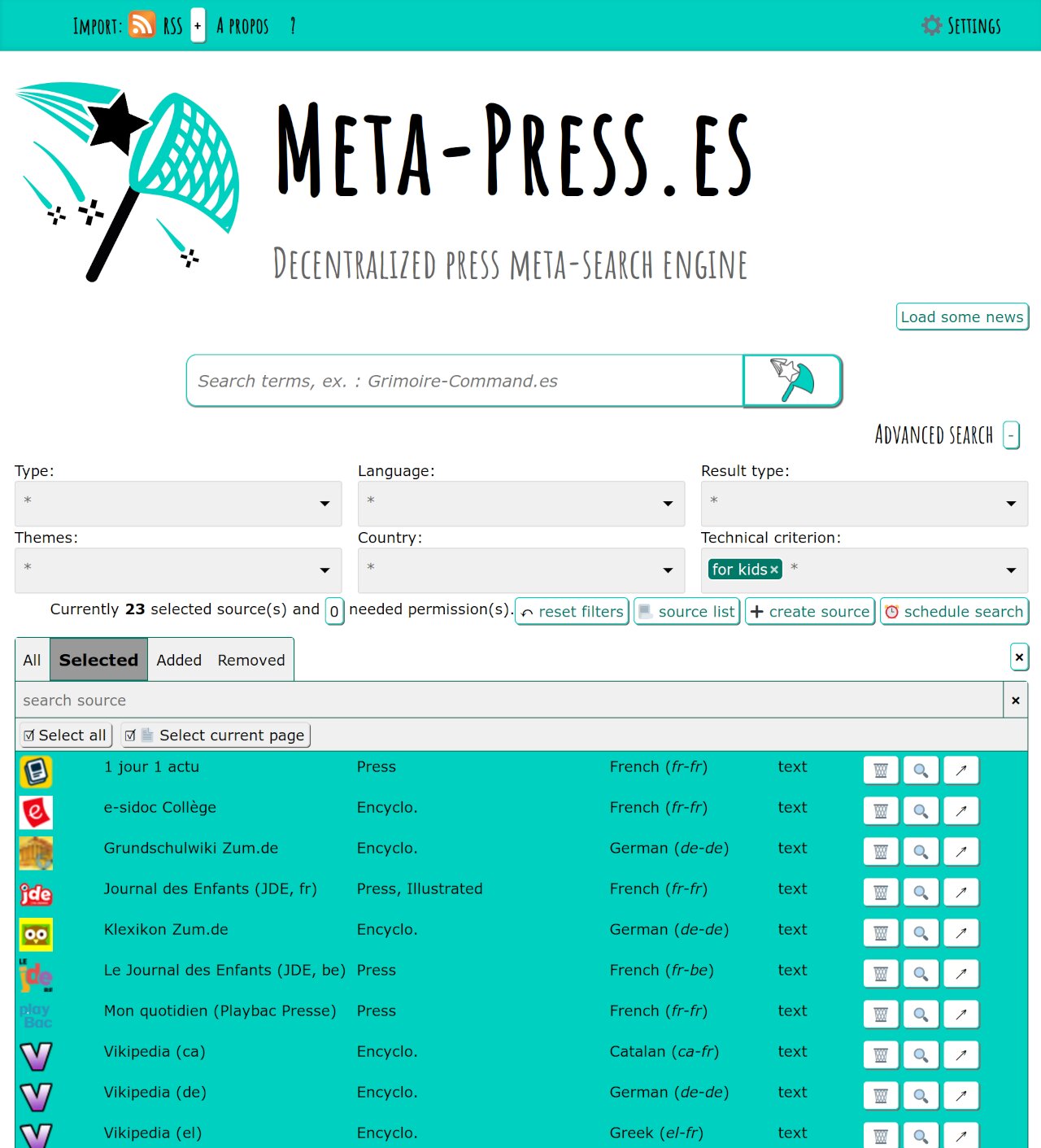
Il y a pour l’instant 26 sources compatibles avec le mode enfant et vous êtes chaudement encouragés à en signaler d’autres pour étoffer la catégorie !
Il y a plus de 10 encyclopédies "pour enfants" en Europe… Elles seront toutes dans la prochaine version de Meta-Press.es #metapress (v1.8.6) et "seulement elles" avec le mode enfants ! Si vous connaissez des sources (journaux en ligne) "pour enfants" c'est le moment !! (de me les signaler) Source : https://fr.wikipedia.org/wiki/WikiKids
- 5 août 2022 à 13:27 - https://pouet.chapril.org/@metapress/108770494843123872

Par Ziko van Dijk — Travail personnel Map children wiki encyclopedias in Europe Jan 2015.pdf, CC BY-SA 4.0, Lien
2. Actu RSS
Concernant les gros titres, un changement radical a eu lieu et ils sont désormais récupérés depuis les flux RSS principaux des sources (qui en proposent). Cela apporte 3 améliorations :
-
les sources compatibles fournissent maintenant 10 actu. ou plus (via réglage)
-
une description accompagne chaque actu
-
la moitié des actus sont même illustrées désormais !
Meta-Press.es ne vise pas à devenir un agrégateur de flux RSS, mais c’était dommage de se passer des flux RSS des sources indexées. Si vous cherchez l’inspiration avant de faire une recherche, maintenant y’a de quoi faire.
Un réglage a été ajouté pour choisir combien d’actu. de chaque source sont affichées dans la liste.
Dans mon instance de Meta-Press.es, j’ai enregistré une "recherche programmée"
avec mes sources indépendantes favorites (parmi les 224 désormais
disponibles). Je la laisse sur la fréquence d’exécution par défaut, c’est à
dire Stop et l’ouvre depuis la page des réglages pour lire l’actu. Par
ailleurs, indep. n’est plus un type de source mais un critère technique
désormais, ce qui permet de croiser ce critère avec les types de source
justement (comme: encyclo. press agenda …).
Cette modification a entrainé une modification de la façon dont les sources sont définies. J’ai scripté une mise à jour des (plus de) 600 sources connues et un flux RSS a été trouvée pour une source sur deux. Il en manque donc probablement encore, et peut être sur des sources que vous connaissez, alors n’hésitez pas à les signaler, c’est facile à ajouter pour la prochaine version.
Cette modification a permis de simplifier les définitions de source (en remplaçant plusieurs champs par un seul news_rss_url. Et puis, même si on perd les actu. de la moitiés des sources pour l’instant, c’est aussi une grosse simplification dans la maintenance de l’outil car au moins les 2/3 des mises à jour de définition de source concernaient les gros titres (car les journaux rivalisent d’inventivité quand il s’agit de mettre un gros titre en avant, alors qu’il y a un dossier spécial à la Une et un live en cours !). Là, avec les flux RSS, la principale évolution envisagée c’est la suppression du flux or ça fait des décennies déjà qu’on a annoncé leur mort…
Une autre modification indirectement apportée à la définition des sources par
cette fonctionnalité est la suppression des entrées xml_type. Il n’y en a
plus besoin. Le travail sur le formulaire dynamique d’ajout de sources a entrainé
la création d’une fonction "detect_RSS_variant", qui a été ré-utilisée pour la
lecture des actu. depuis leurs flux et finalement étendue (vu les bons
résultats dans la détection des illustrations) aux résultats de recherche des
sources définies via flux RSS. Définir une nouvelle source est donc plus simple
aujourd’hui avec ces petites simplifications et le formulaire de création de
source a été mis à jour en conséquence.
Le résultat le plus concret de ce changement c’est qu’il y a plus d’illustrations dans les résultats affichés par Meta-Press.es (vu qu’on en avait sûrement manqués dans les définitions manuelles).
La documentation en ligne du projet a également été mise à jour (et c’est le genre de phrase qui reflète mal tout le travail que ça a demandé).
3. Des sources "originales" et d’autres plus sérieuses…
Il y a des sources qui devraient être faciles à indexer, vu qu’elles fournissent leurs résultats de recherche en RSS, mais dont l’intégration échoue quand même, parce que leur RSS ne comporte pas de date sur ses entrées ! C’est notamment le cas du DailyTelegraph.com ou d’Arabnews.jp (les deux ayant été découverts le même soir) :
Faîtes moi un maximum de bruit pour le Daily Telegraph qui réussi l'exploit de publier un flux #RSS à moitié vide, sans date sur les résultats !! https://www.dailytelegraph.com.au/news/breaking-news/rss Sur 235 flux RSS gérés par la prochaine version de #metapress c'est le seul qui est pété à ce point. La bonne nouvelle, c'est que la lecture d'actualités générales depuis Meta-Press.es prend une autre tournure : 10 actu par sources, descriptions et illustrations… Et stable comme du RSS, alors que c'était le pire à maintenir.
- 9 août 2022 à 19:15 - https://pouet.chapril.org/@metapress/108794515280867796
Il y a des sources qui se prennent très au sérieux, comme
IntelligenceOnline.fr traitant de sécurité
au sens large et scrutant les agences de renseignement. Il a déjà fallu
améliorer des points de Meta-Press.es pour tenter d’intégrer cette source, en
créant notamment l’entrée search_ctype qui permet de préciser le
content-type des données envoyées au serveur pour faire une recherche (car
les 608 premières sources de Meta-Press.es se contentaient du format
application/x-www-form-urlencoded mais qu’IntelligenceOnline.fr préfère utiliser
l' application/json). Et ce ne fut pas suffisant pour ajouter cette source,
car elle chiffre les termes de recherche avant de les envoyer au serveur !
Du coup, sur le principe c’est généré par du JavaScript côté client, donc c’est étudiable et je serai heureux d’ajouter de nouvelles entrées term_cipher_method et term_cipher_key au format de définition des sources…
Mais vu que ça ne va pas être dans mes priorité tout de suite, un valeureux contributeur pourrait gagner beaucoup de considération, des autocollants et des badges de Meta-Press.es ainsi qu’un billet sur ce blog (10k visiteurs uniques mensuels) revenant en détail sur son aventure… J’ai créé le bug suivant dans Framagit pour suivre le sujet : https://framagit.org/Siltaar/meta-press-ext/-/issues/54
| 2024-02-26 : un mécanisme de requête préliminaire permettant la récupération d’un jeton à injecter dans l’URL de recherche a été implémenté et documenté. Il règle ce problème. |
Pour finir, parlons d’une tendance qui m’étonne…
Tout d’abord, il y a encore des sources qui utilisent le protocole jsonp pour
servir leurs résultats de recherche (il s’agit d’un moyen de contourner
certaines sécurités mises en place dans l’accès aux ressources JSON, et c’était
très utilisé il y a une vingtaine d’années). C’est notamment le cas de
LaNacion.com.ar (alors bon d’accord, l’Argentine c’est dans la moitié sud du
globe, le climat du pays est fou et il y a eu une crise économique terrible il
y a 20 ans…) mais c’est aussi le cas de Liberation.fr. Du coup il existe une
entrée de définition de source nommée jsonp_to_json_re qui permet de spécifier
un motif de remplacement par expression rationnelle utilisé pour extraire les
données JSON d’un script JSONP.
Mais il y a aussi le contraire qui émerge sur le web en ce moment… du JSON
utilisé pour encapluser du HTML normal, calculé côté serveur. Pourquoi ne pas
se contenter d’envoyer du HTML (comme tout le monde). Du coup il existe une
entrée json_to_html dans les définitions de source qui permet de préciser un
chemin JSON où trouver du contenu HTML à analyser pour la suite et je sens qu’il
va bientôt falloir affiner ce mécanisme champs par champs…
 Installation via Mozilla
Installation via Mozilla
 Sources via Framagit
Sources via Framagit
 Sponsor via Liberapay
Sponsor via Liberapay
 Sponsor via HelloAsso
Sponsor via HelloAsso
 Social via Mastodon
Social via Mastodon
 Wau Holland Stiftung
Wau Holland Stiftung
